

Which Registers Are Read In A Sw Operation Mips Pipeline
10 Pipelining – MIPS Implementation
Dr A. P. Shanthi
The objectives of this module are to discuss the nuts of pipelining and hash out the implementation of the MIPS pipeline.
In the previous module, we discussed the drawbacks of a unmarried wheel implementation. We observed that the longest delay determines the clock menses and it is not feasible to vary period for different instructions. This violates the design principle of making the mutual instance fast. I way of overcoming this trouble is to go in for a pipelined implementation. Nosotros shall at present discuss the basics of pipelining. Pipelining is a particularly effective mode of organizing parallel action in a computer organisation. The basic idea is very simple. It is often encountered in manufacturing plants, where pipelining is commonly known as an associates line operation. Past laying the production process out in an assembly line, products at various stages can be worked on simultaneously. You must take noticed that in an automobile assembly line, you will find that one car's chassis volition be fitted when another car'southward door is getting fixed and another motorcar's torso is getting painted. All these are contained activities, taking place in parallel. This process is also referred to every bit pipelining, considering, as in a pipeline, new inputs are accepted at i finish and previously accustomed inputs announced equally outputs at the other end. Equally yet some other real world example, Consider the case of doing a laundry. Presume that Ann, Brian, Cathy and Daveeach have one load of clothes to wash, dry, and fold and that the washer takes xxx minutes, dryer takes twoscore minutes and the folder takes 20 minutes. Sequential laundry takes 6 hours for 4 loads. On the other hand, if they learned pipelining, how long would the laundry take? It takes simply 3.v hours for iv loads! For 4 loads, you get a Speedup = half-dozen/iii.v = ane.7. If you work the washing machine non-stop, y'all get a Speedup = 110n/40n + seventy ≈ 3 = number of stages.
To utilise the concept of pedagogy execution in pipeline, it is required to pause the instruction execution into different tasks. Each task will be executed in different processing elements of the CPU. As we know that in that location are ii singled-out phases of instruction execution: one is instruction fetch and the other one is instruction execution. Therefore, the processor executes a programme past fetching and executing instructions, one later another. The cycle time τ of an educational activity pipeline is the time needed to advance a set of instructions ane stage through the pipeline. The bike fourth dimension can be determined as
![]()
where τm = maximum stage delay (delay through the stage which experiences the largest delay) , k = number of stages in the instruction pipeline, d = the time delay of alatch needed to advance signals and information from 1 stage to the next. At present suppose that due north instructions are processed and these instructions are executed 1 after another. The full time required Tk to execute all n instructions is
![]()
In general, let the didactics execution be divided into five stages as fetch, decode, execute, memory access and write back, denoted by Fi, Di, Ei, Mi and Wi. Execution of a programme consists of a sequence of these steps. When the first teaching'due south decode happens, the 2d instruction'southward fetch is washed. When the pipeline is filled, you see that there are five unlike activities taking place in parallel. All these activities are overlapped. V instructions are in progress at any given fourth dimension. This ways that five distinct hardware units are needed. These units must be capable of performing their tasks simultaneously and without interfering with one another. Information is passed from one unit to the next through a storage buffer. As an instruction progresses through the pipeline, all the information needed past the stages downstream must exist passed forth.
If all stages are counterbalanced, i.due east., all take the same time,

If the stages are not counterbalanced, speedup will be less. Observe that the speedup is due to increased throughput and the latency (time for each didactics) does not decrease.
The bones features of pipelining are:
• Pipelining does not help latency of single job, it only helps throughput of entire workload
• Pipeline rate is limited by the slowest pipeline phase
• Multiple tasks operate simultaneously
• Information technology exploits parallelism among instructions in a sequential pedagogy stream
• Unbalanced lengths of pipe stages reduces speedup
• Time to "fill up" pipeline and fourth dimension to "drain" information technology reduces speedup
• Ideally the speedup is equal to the number of stages and the CPI is 1
Let the states consider the MIPS pipeline with v stages, with one pace per stage:
• IF: Instruction fetch from memory
• ID: Educational activity decode & annals read
• EX: Execute performance or calculate address
• MEM: Access retention operand
• WB: Write effect back to register
Consider the details given in Effigy x.1. Assume that it takes 100ps for a annals read or write and 200ps for all other stages. Let us calculate the speedup obtained by pipelining.
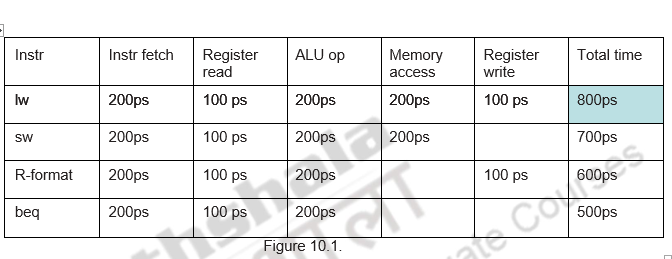

Figure 10.ii
For a not pipelined implementation it takes 800ps for each instruction and for a pipelined implementation it takes only 200ps.
Observe that the MIPS ISA is designed in such a way that it is suitable for pipelining.
Figure 10.3 shows the MIPS pipeline implementation.
– All instructions are 32-bits
- Easier to fetch and decode in 1 cycle
- Comparatively, the x86 ISA: 1- to 17-byte instructions
– Few and regular educational activity formats
- Tin can decode and read registers in one step
– Load/store addressing
- Can calculate address in 3rd phase, access retention in 4th stage
– Alignment of memory operands
- Memory admission takes only one wheel


Effigy 10.4 shows how buffers are introduced betwixt the stages. This is mandatory. Each stage takes in data from that buffer, processes it and write into the next buffer. Also note that as an instruction moves down the pipeline from i buffer to the side by side, its relevant information also moves along with it. For example, during clock cycle 4, the information in the buffers is equally follows:
- Buffer IF/ID holds teaching I4, which was fetched in cycle iv
- Buffer ID/EX holds the decoded instruction and both the source operands for instruction I3. This is the information produced by the decoding hardware in cycle 3.
- Buffer EX/MEM holds the executed result of I2. The buffer also holds the information needed for the write pace of instruction I2. Fifty-fifty though information technology is not needed by the execution stage, this information must be passed on to the adjacent stage and further downward to the Write back stage in the post-obit clock cycle to enable that phase to perform the required Write performance.
- Buffer MEM/WB holds the data fetched from memory (for a load) for I1, and for the arithmetic and logical operations, the results produced by the execution unit and the destination data for didactics I1 are simply passed.
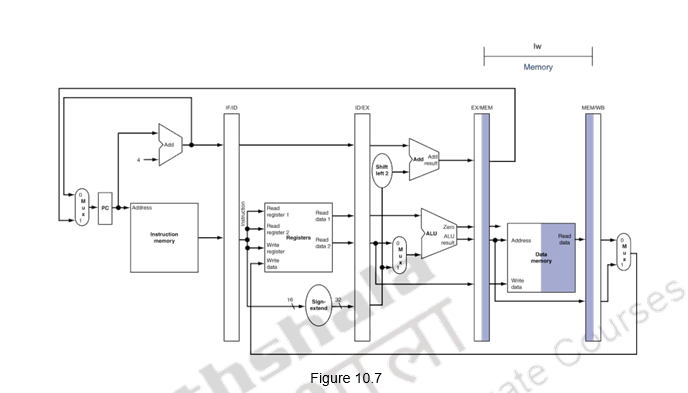
Nosotros shall wait at the unmarried-clock-bicycle diagrams for the load & store instructions of the MIPS ISA. Figure 10.4 shows the instruction fetch for a load / store didactics. Discover that the PC is used to fetch the instruction, it is written into the IF/ID buffer and the PC is incremented by 4. Figure 10.5 shows the next phase of ID. The instruction is decoded, the register file is read and the operands are written into the ID/EX buffer. Notation that the entire information of the instruction including the destination register is written into the ID/EX buffer. The highlights in the figure show the resources involved. Effigy x.6 shows the execution stage. The base register'southward contents and the sign extended displacement are fed to the ALU, the addition operation is initiated and the ALUcalculates the memory address. This effective address is stored in the EX/MEM buffer. Also the destination register's information is passed from the ID/EX buffer to the EX/MEM buffer. Next, the memory access happens and the read data is written into the MEM/WB buffer. The destination annals's data is passed from the EX/MEM buffer to the MEM/WB buffer. This is illustrated in Figure 10.7. The write back happens in the last phase. The data read from the data retention is written into the destination register specified in the educational activity. This is shown in Figure x.8. The destination register data is passed on from the MEM/WB memory backwards to the register file, forth with the data to be written. The datapath is shown in Figure x.ix.



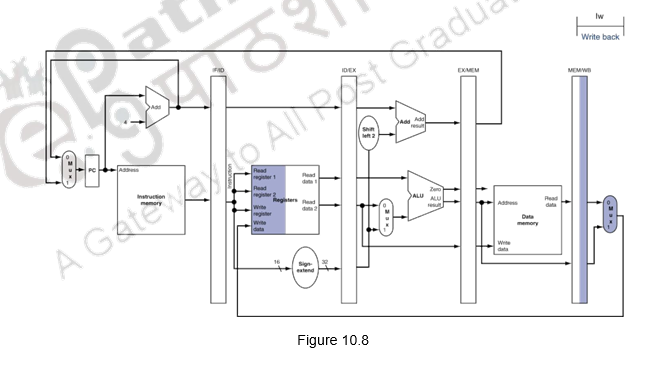

For a store pedagogy, the effective address calculation is the same as that of load. But when it comes to the memory admission stage, store performs a memory write. The effective address is passed on from the execution stage to the retentiveness stage, the data read from the annals file is passed from the ID/EX buffer to the EX/MEM buffer and taken from there. The store instruction completes with this retentivity stage. At that place is no write back for the store instruction.
While discussing the cycle-by-cycle flow of instructions through the pipelined datapath, nosotros can expect at the following options:
- "Single-clock-bicycle" pipeline diagram
- Shows pipeline usage in a unmarried bike
- Highlight resource used
- o "multi-clock-cycle" diagram
- Graph of performance over time
The multi-clock-cycle pipeline diagram showing the resources utilization is given in Figure 10.10. Information technology can exist seen that the Instruction memory is used in eth kickoff phase, The annals file is used in the second stage, the ALU in the tertiary stage, the data memory in the 4th stage and the annals file in the 5th stage again.
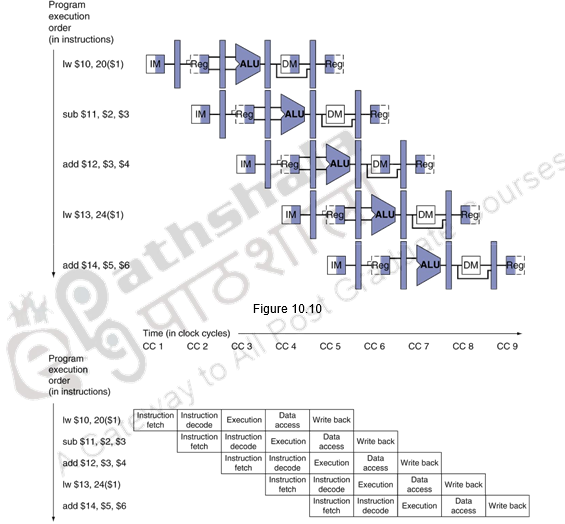
Figure 10.11
The multi-wheel diagram showing the activities happening in each clock cycle is given in Figure 10.11.
Now, having discussed the pipelined implementation of the MIPS architecture, we need to discuss the generation of control signals. The pipelined implementation of MIPS, along with the control signals is given in Figure 10.12.

All the control signals indicated are not required at the same time. Different command signals are required at different stages of the pipeline. But the conclusion about the generation of the various command signals is done at the 2d stage, when the instruction is decoded. Therefore, just as the data flows from one phase to another every bit the educational activity moves from i stage to another, the control signals also pass on from ane buffer to another and are utilized at the appropriate instants. This is shown in Figure 10.13. The control signals for the execution stage are used in that stage. The control signals needed for the retentiveness stage and the write back stage motion along with that instruction to the next stage. The retention related command signals are used in the next stage, whereas, the write back related control signals move from there to the next stage and used when the didactics performs the write back operation.

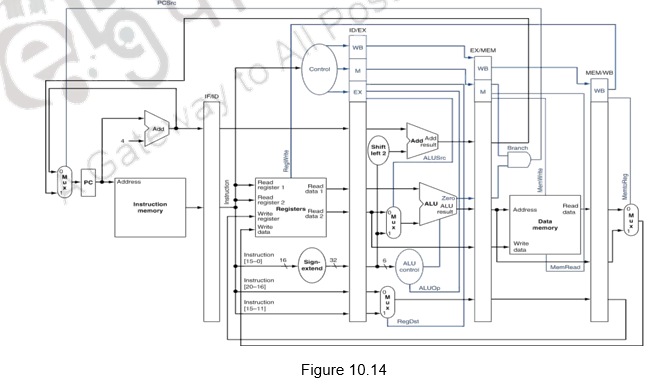
The complete pipeline implementation, along with the control signals used at the various stages is given in Effigy 10.14.
To summarize, we have discussed the basics of pipelining in this module. We have made the post-obit observations nigh pipelining.
- Pipelining is overlapped execution of instructions
- Latency is the same, but throughput improves
- Pipeline rate limited by slowest pipeline stage
- Potential speedup = Number of pipe stages
Nosotros have discussed about the implementation of pipelining in the MIPS architecture. We have shown the implementation of the various buffers, the data catamenia and the control period for a pipelined implementation of the MIPS architecture.
Spider web Links / Supporting Materials
- Estimator Organization and Blueprint – The Hardware / Software Interface, David A. Patterson and John 50. Hennessy, 4th.Edition, Morgan Kaufmann, Elsevier, 2009.
- Figurer Organization, Carl Hamacher, Zvonko Vranesic and Safwat Zaky, 5th.Edition, McGraw- Hill College Pedagogy, 2011.

Which Registers Are Read In A Sw Operation Mips Pipeline,
Source: https://www.cs.umd.edu/~meesh/411/CA-online/chapter/pipelining-mips-implementation/index.html
Posted by: bullardwhictime.blogspot.com
0 Response to "Which Registers Are Read In A Sw Operation Mips Pipeline"
Post a Comment